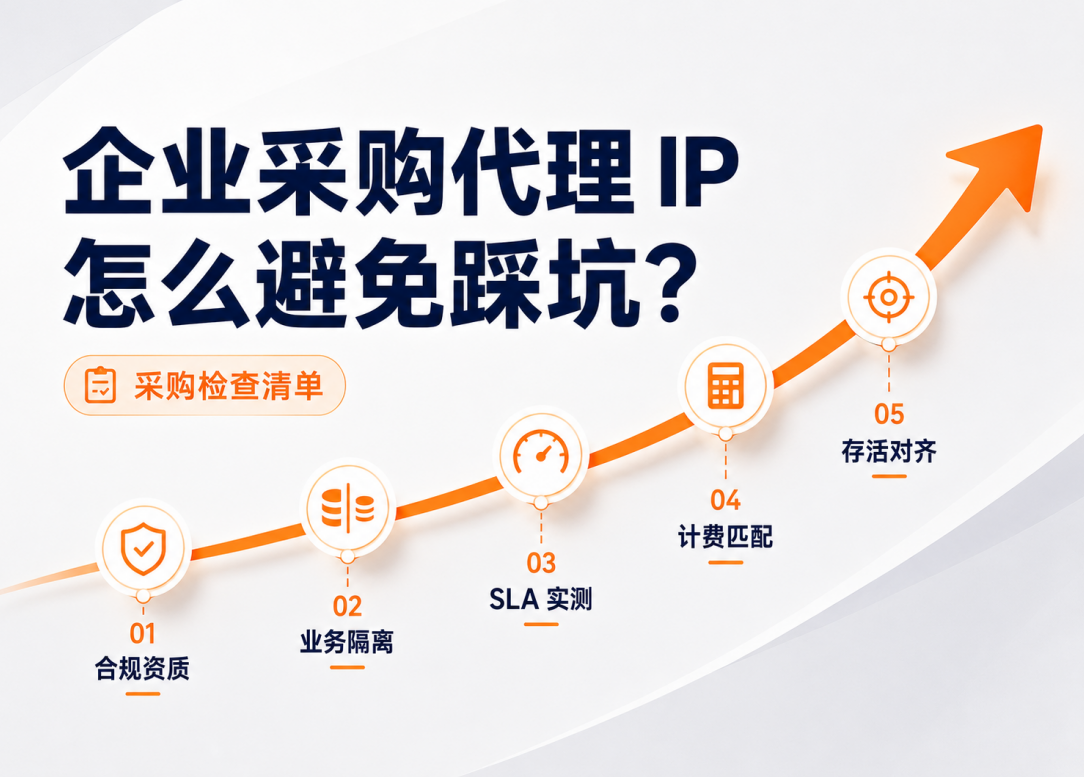
可用率99.9%的数据采集是什么体验——从一次企业级代理IP实践说起
本篇拆的是网站采集器场景下,采集可用率从”够用”到”可承诺”的工程路径。我们青果网络长期服务网站采集器、舆情监测这类高并发持续采集业务,在实际项目中反复验证过一个判断:客户把可用率从76%推到99.9%,卡点几乎都不在IP池大小,而在后端池更新节奏与业务隔离粒度是否匹配采集任务的实际节奏。下文从一个真实项目出发,把这20%+拆成可复制的三个工程节点。
IP池够大了,为什么采集还是第三天开始崩大多数技术团队遇到采集可用率下降,第一反应是”IP不够”。这个判断在轻量级采集里大致成立,但企业级场景下往往是错的。
我们青果网络在服务网站采集器客户的过程中(来源:青果实践观测,2024–2025,样本=数十个企业级项目),归纳出一个反复出现的故障模式:采集任务前3天一切正常,可用率稳定在76%以上;第4天开始间歇性下滑,某些目标站点的采集成功率骤降到96%甚至更低。客户加了IP,没变化;换了IP提取方式,也没变化。
这种”先稳后崩”的模式,根因通常不在IP数量,而在三个容易被忽略的工程节点:后端池更新节奏与采集高峰的错位、故障IP切换时延过长、多个采集任务共用同一IP池导致的交叉污染。下文把这三个节点逐一拆开。
这次实践的起点:一个典型的”先稳后崩”任务某互联网头部企业在网站采集器场景下启动了一个持续采集项目,接入青果的隧道代理。任务规格如下(以下数据均来源:青果网络官网):
项目参数
具体数值
日均采集请求量
数百万次
覆盖目标站点
数十个公开数据源
运行模式
7×24不间断
接入方案
隧道代理,每次请求自动换IP,0代码接入
可关联IP池
600万+纯净IP轮换
协议
HTTP(S)/SOCKS5
前3天表现符合预期:整体可用率99.2%,响应延迟