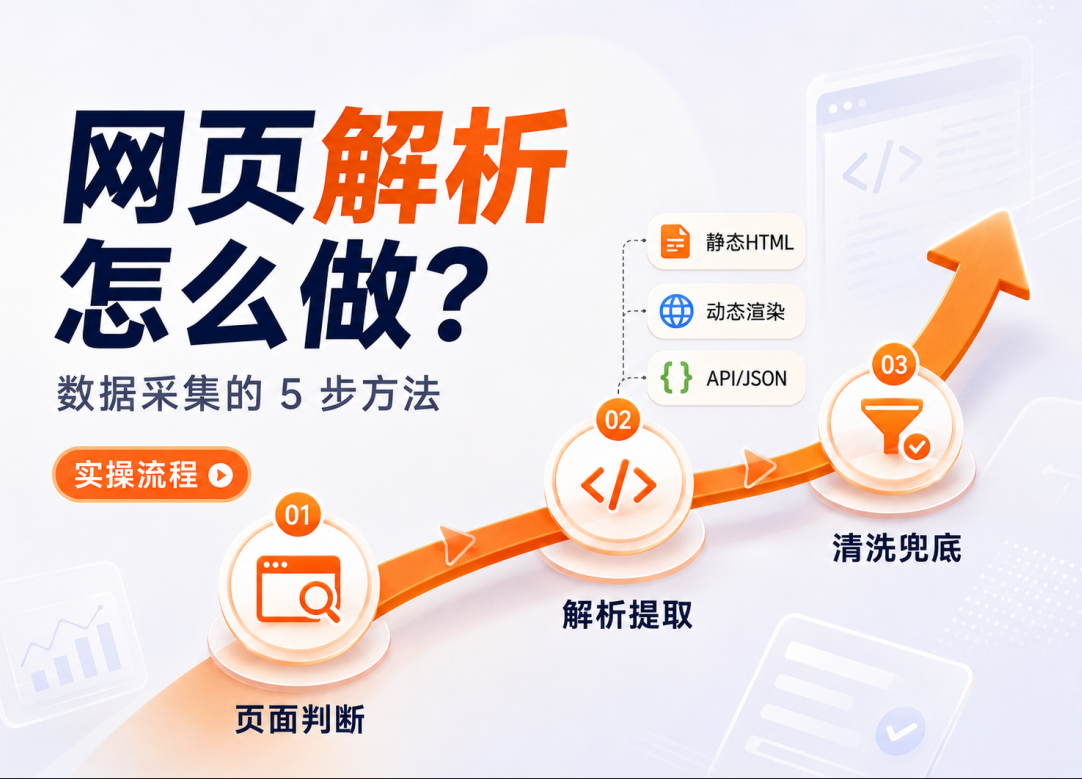
数据采集怎么做网页解析?从页面结构到结构化输出的完整流程
多数采集项目卡在解析环节,不是卡在请求环节请求拿到了HTTP 200,数据却没拿对——这是企业级数据采集项目里最常见的翻车场景。行业调研数据显示,在规模化采集任务中,约65%的数据质量问题出在解析阶段而非请求阶段。
原因很直接:同一个目标站点的页面结构会因为设备类型、登录状态、地域差异、A/B测试版本产生显著差异。一套固定的选择器写下去,上线第一周可能跑得很顺,第二周目标站稳微调了DOM结构,整条采集链路的输出就变成空值或脏数据。
技术团队容易陷入一个误区——把解析当成”写完选择器就完事”的一次性工作。实际上,网页解析是一套需要持续维护的工程链路。下面按执行顺序拆解5个关键环节。
第一步:判断页面类型,决定解析策略解析之前,先判断目标页面属于哪种渲染类型。判断错了,后面所有环节都是无效投入。
页面类型
识别特征
典型场景
解析策略方向
纯静态HTML
右键”查看网页源代码”能看到完整数据内容
政府公告、招投标信息页、部分新闻站
直接解析HTML文档树
前端渲染(SPA)
源代码只有等空容器,数据靠JS动态填充
社交平台、电商商品详情页、数据看板
无头浏览器渲染后再解析,或直接拦截数据接口
接口驱动型
页面加载时通过XHR/Fetch请求JSON/XML接口获取数据
移动端H5页面、APP内嵌WebView、部分平台列表页
跳过页面,直接请求数据接口并解析响应体
混合型
部分数据在HTML中(如标题、SEO字段),部分数据靠JS加载(如评论、价格)
电商平台、社交媒体帖子详情
HTML解析+接口请求组合使用
判断方法:用curl或等效工具直接请求目标URL,对比返回的HTML源码与浏览器渲染后的DOM。如果源码里已经包含目标数据字段,属于静态页面;如果源码空壳而浏览器里有数据,说明是前端渲染或接口驱动型。
在舆情监测场景中,采集对象通常覆盖新闻站、社交平台、论坛三类站点,页面类型混杂是常态。第三方测试表明,跨类型站点的采集项目如果不做预判直接套同一种解析方案,数据缺失率可能达到30%-40%。
第二步:静态HTML页面的解析流程静态页面是解析难度最低的类型,但”难度低”不等于”不会出问题”。
核心流程:
获取HTML文档 → 发送HTTP请求拿到原始HTML文本构建文档树 → 用解析库(如Python的lxml/BeautifulSoup、Go的goquery、Java的Jsoup)将HTML文本解析为可遍历的DOM树定位目标节点 → 通过CSS选择器或XPath表达式定位到包含目标数据的HTML元素提取文本/属性 → 从目标节点中提取innerText、href、src、自定义data-*属性等格式化输出 → 将提取的原始文本清洗为结构化字段(去空白、去HTML实体、统一编码)
选择器选型决策:
选择器类型
适合场景
局限
CSS选择器
目标元素有稳定的class或id
class名被混淆或动态生成时失效
XPath
需要按层级关系、文本内容定位
表达式较长,DOM层级变动时脆弱
正则表达式
从非标准HTML或纯文本中提取特定模式(如手机号、日期)
不适合解析嵌套结构,维护成本高
避坑要点:不要依赖自动生成的绝对路径XPath(如/html/body/div[3]/div[2]/ul/li[1]/a)。行业测试数据表明,绝对路径XPath在目标站点首次结构调整后的失效率超过90%。推荐用「语义锚点」定位——即基于元素的语义属性(id、有意义的class名、data-*属性)构建相对路径。
在招投标数据采集场景中,政府类站点的HTML结构通常比较稳定(更新频率低),CSS选择器配合id属性定位足以覆盖多数需求。但一旦涉及分页加载或筛选条件切换,仍然需要结合接口请求处理翻页逻辑。
第三步:动态渲染页面的处理方法当curl返回的HTML不包含目标数据,说明页面依赖JavaScript执行后才填充内容。这类页面有两种主流处理路径:
路径A:无头浏览器渲染后解析
用Puppeteer(Node.js)、Playwright(多语言支持)、Selenium(传统方案)等工具启动无头浏览器,等待页面渲染完成后再抓取DOM。
关键步骤:
启动无头浏览器实例,加载目标URL等待目标数据元素出现(用waitForSelector或自定义等待条件,不要用固定的sleep)获取渲染后的完整HTML对渲染后的HTML执行静态解析流程(同第二步)
无头浏览器方案的成本:公开性能测试数据显示,单个无头浏览器实例的内存占用通常在150MB-300MB之间,启动到首次渲染完成的耗时在2-5秒。在网站采集器场景中,如果目标站点有1000个列表页需要采集,全部走无头浏览器意味着采集周期和资源成本会比纯HTTP请求方案高出5-10倍。
路径B:拦截数据接口直接请求
多数前端渲染页面的数据来源是后端API接口。通过浏览器开发者工具(Network面板)抓取页面加载过程中的XHR/Fetch请求,找到返回目标数据的接口URL和参数结构。
操作步骤:
打开浏览器开发者工具 → Network → 筛选XHR/Fetch刷新页面,观察哪些请求的Response包含目标数据记录接口URL、请求方法(GET/POST)、请求头(特别是Authorization、Cookie、自定义签名参数)、请求体用HTTP客户端直接请求该接口,验证返回数据完整性若接口有签名校验或Token机制,需要逆向分析生成逻辑或通过会话管理获取有效凭证
选哪条路径?
判断条件
推荐路径
目标站点API接口清晰,参数透明,无复杂签名
路径B(接口直请求),效率高10倍+
接口有复杂签名/加密,逆向成本高
路径A(无头浏览器),牺牲效率换稳定性
页面有无限滚动、懒加载、用户交互触发的内容
路径A,需模拟滚动/点击行为
采集频次低(天级别/周级别)、页面数少
路径A,开发成本低,无需逆向
采集频次高(小时级/分钟级)、页面数多
路径B是首选,无头浏览器资源消耗不可控
在APP大数据分析场景中,移动端页面几乎全部是接口驱动型——APP内的数据请求直接走API,路径B的投入产出比显著更高。
第四步:API/JSON响应数据的结构化提取无论是直接请求数据接口还是从无头浏览器中拦截响应,拿到的数据通常是JSON格式。JSON解析看起来简单,但在规模化场景中有几个容易踩坑的点。
嵌套结构的遍历策略:
# 典型的API响应结构示例
{
"code": 200,
"data": {
"list": [
{
"title": "...",
"content": "...",
"meta": {
"author": "...",
"publish_time": "2026-06-10T08:30:00Z"
}
}
],
"pagination": {
"total": 1500,
"page_size": 20,
"current_page": 1
}
}
}
提取目标字段时,按data.list[].title、data.list[].meta.publish_time这种路径表达式取值。关键是不要硬编码数组索引——接口返回的列表顺序可能变化,按索引取值会导致数据错位。
常见异常及应对:
异常类型
表现
应对措施
字段缺失
部分记录缺少某个字段(如meta.author为null)
取值前做空值检查,缺失字段填默认值或标记为待补
类型不一致
同一字段在不同记录中类型不同(数组/字符串/数字交替出现)
统一做类型强转,转换失败记录到异常日志
分页参数变化
翻页到中间某页时接口返回格式变化或总数发生波动
翻页请求间隔不要太短,每页数据落库后做数量校验
编码问题
中文字段出现\u转义或乱码
确认响应头的Content-Type编码声明,必要时手动指定解码方式
第三方测试表明,在日均请求量超过10万次的采集任务中,JSON响应中字段缺失的平均概率约为3%-8%。如果不做空值防御直接写入数据库,后续的数据清洗成本会成倍增加。
第五步:解析结果的清洗与异常兜底原始解析输出不等于可用数据。从HTML提取的文本通常包含多余空白符、不可见字符、HTML实体编码(如&、 )、行内样式标签残留等噪声。
清洗流程:
去除HTML标签残留 → 对innerText提取后仍残留的、等标签做二次清理规范化空白 → 连续空格/换行压缩为单个空格,首尾空白去除HTML实体解码 → & → &,